

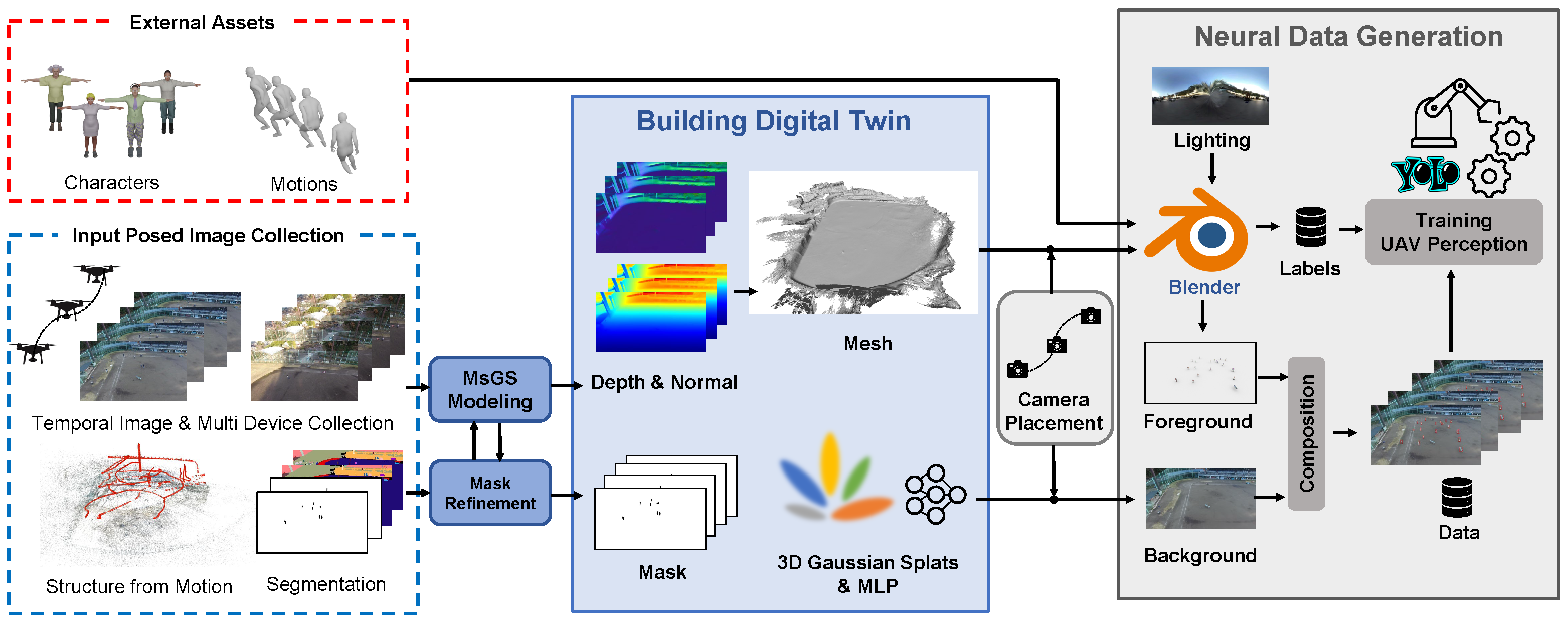
 Our approach first constructs a digital twin using UAV-based images captured at different times. We introduce MsGS, a novel 3DGS method to analyze varying appearance images and reconstruct a clean mesh, Gaussian splats, and an MLP for novel-view synthesis. Then, our method generates data by compositing foreground humans rendered in Blender with backgrounds rendered using trained Gaussian splats.
Our approach first constructs a digital twin using UAV-based images captured at different times. We introduce MsGS, a novel 3DGS method to analyze varying appearance images and reconstruct a clean mesh, Gaussian splats, and an MLP for novel-view synthesis. Then, our method generates data by compositing foreground humans rendered in Blender with backgrounds rendered using trained Gaussian splats.

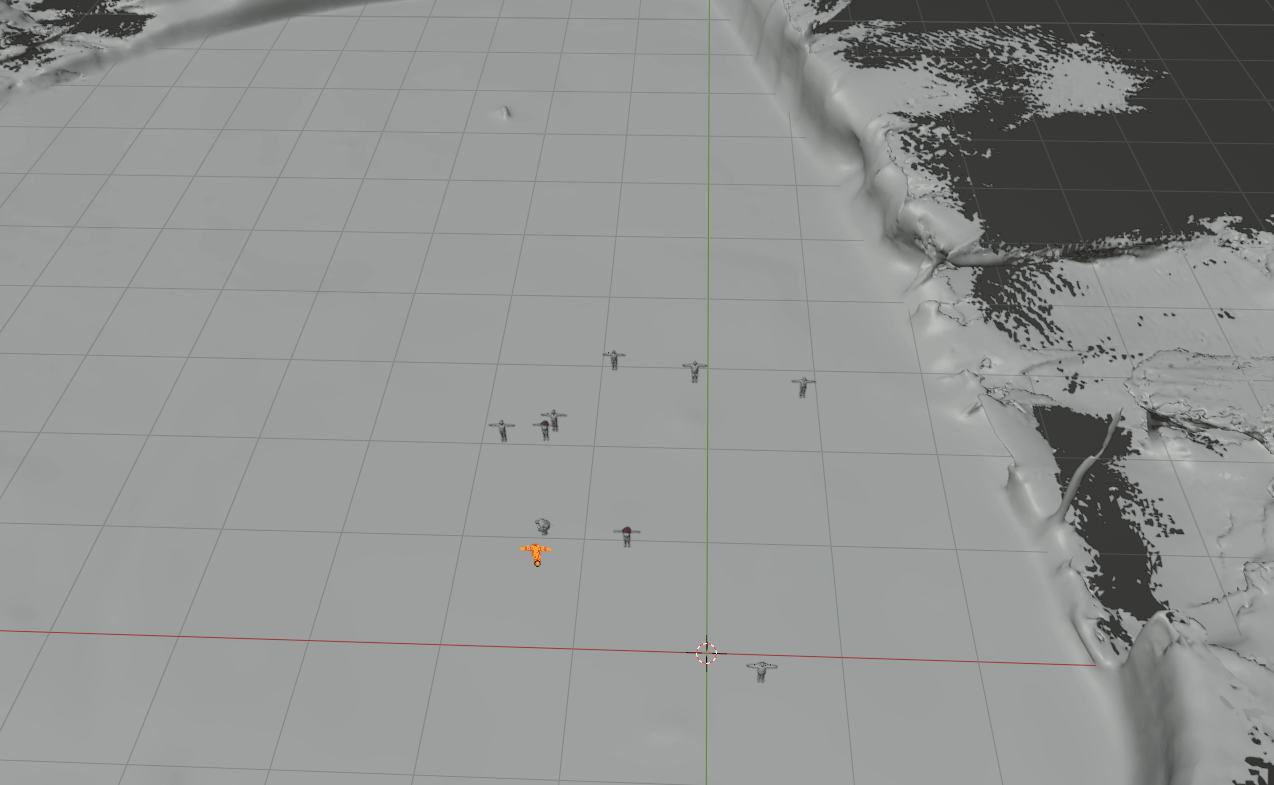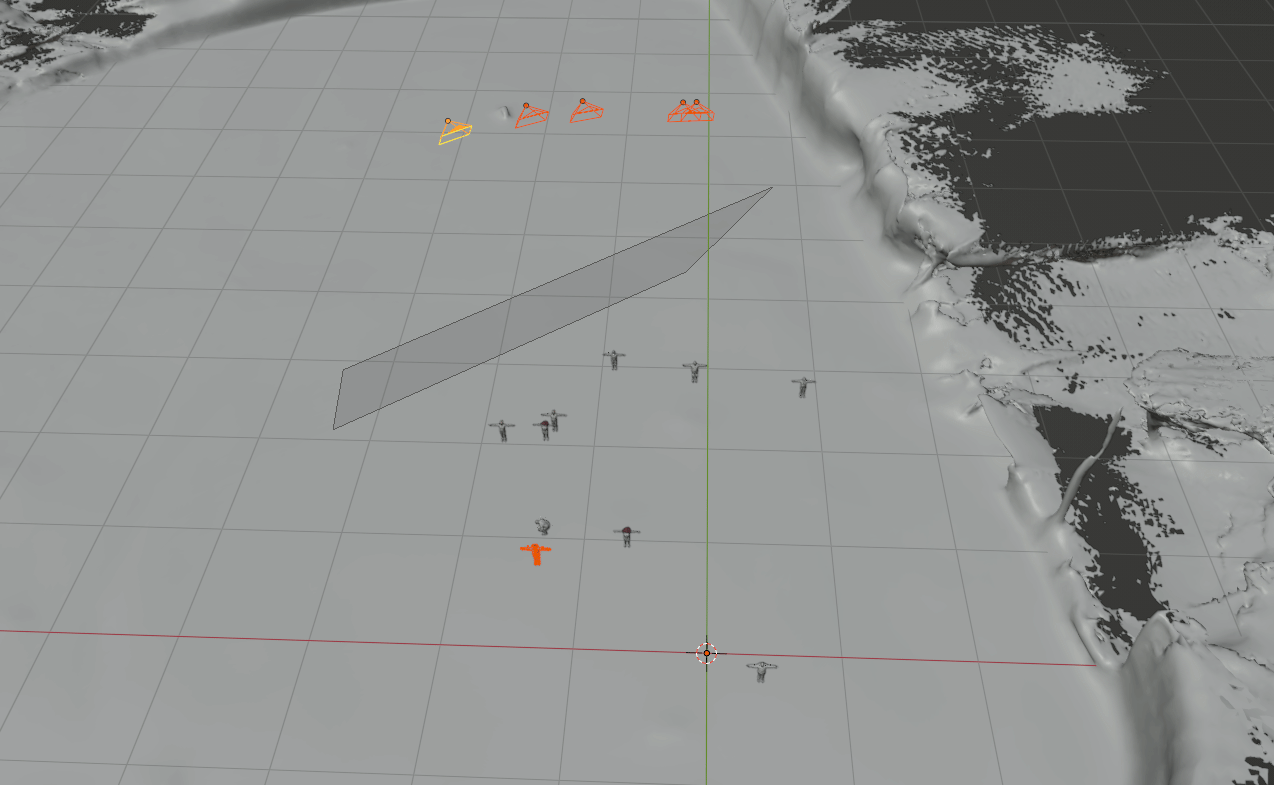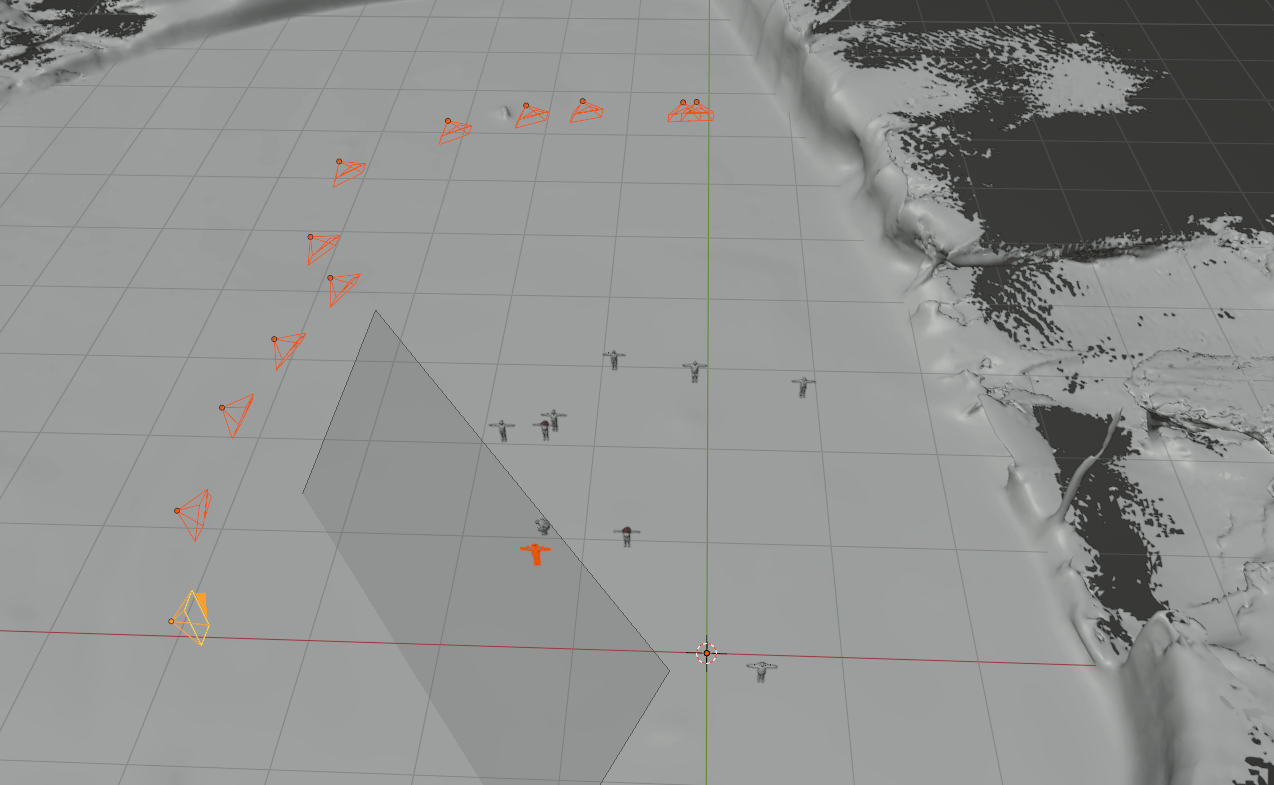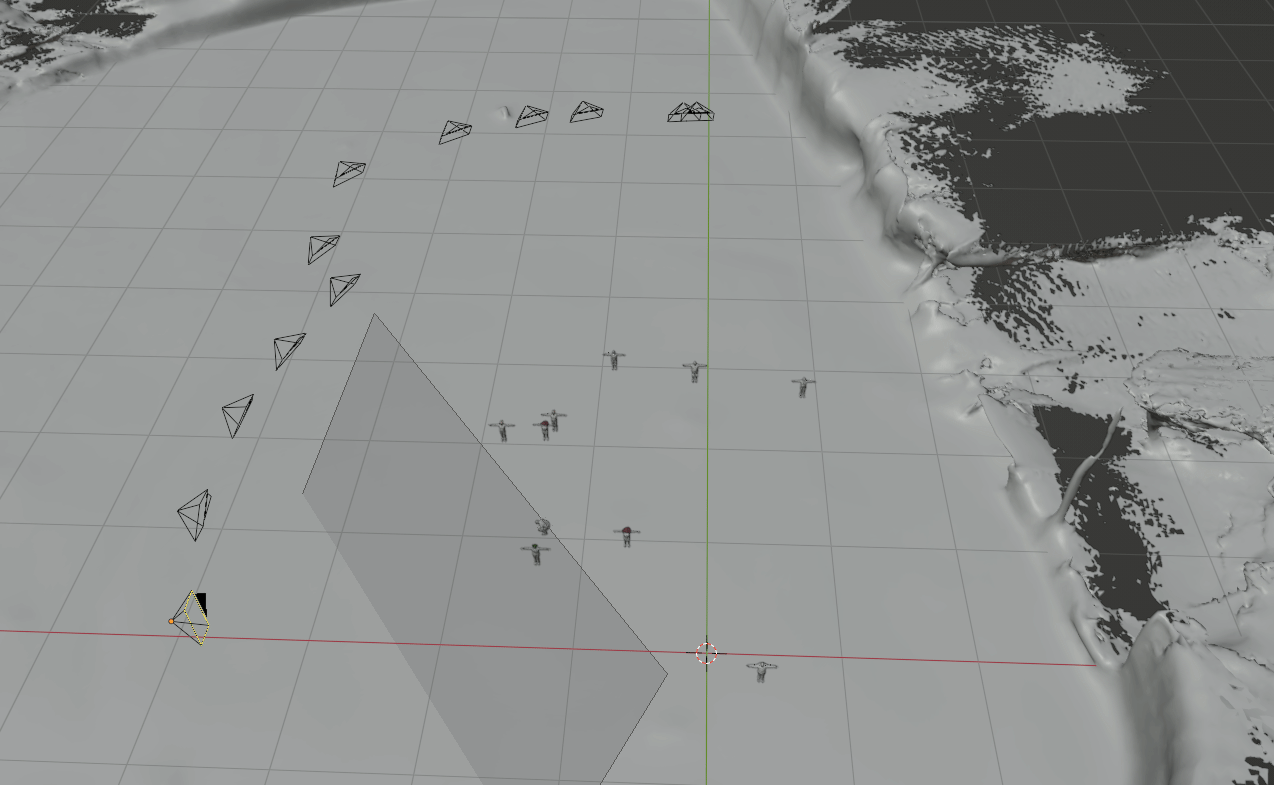

For data generation, our method comprises synthetic human placement, camera trajectory generation, and rendering foreground humans using a graphics engine (e.g. Blender).












Examples of Synthesized Data with Corresponding Labels Generated Using Our Method